

背景介绍
Molecular Transformer是当前最先进的反应预测技术,模型的输入是反应物和化学结构的文本表示,模型执行机器翻译预测最可能的分子和概率分数。目前Molecular Transformer在USPTO有机反应数据集上达到了90%的Top-1准确率。然而,Molecular Transformer的一个难点是其输出结果缺乏可解释性。Molecular Transformer输出某个结构以及找到某个最相似样本的依据我们都尚不清楚。对于模型用户来说,化学反应是前后密切相关的,反应条件、反应规模和项目研究方向是经验丰富的化学家用来解释和了解反应的依据。而对于模型开发人员来说,有机化学原理可以解释化学反应性和选择性。因此,可以通过测试Molecular Transformer输出的基本原理是否与有机化学一致,是否凭借正确的依据得到正确的预测两种方法来改进模型。在本文中,研究者使用输入化学结构和训练数据来定量解释Molecular Transformer的预测结果。研究者展示了模型学习的内容,并揭示了预测错误的原因。同时,研究者还发现了训练数据中阻碍泛化性能和掩盖模型缺陷的隐藏偏差,并通过引入新的无偏差训练/测试分割解决了这个问题。相关的研究成果以“Quantitative Interpretation Explains Machine Learning Models for Chemical Reaction Prediction and Uncovers Bias”为题发表在国际著名杂志Nature Communications上。
主要内容
模型预测的三个关键因素是架构、数据和输入。这三个因素相互作用产生复杂的作用方式,因此存在难以解释的问题。要解释模型预测,首先需要定义可解释性。研究者认为可解释性是发现输入和输出关联的能力,以及在数据中寻找支持结果的证据的能力。研究者采用积分梯度(IG)的方法,使用各部分的输入来解释选择性化学反应中两种产物的预测概率差异,在输入的各部分展示出每个子结构对模型的预测选择性的贡献。如果概率差异在输入中均匀分布,那么获得比平均值更高的积分梯度的结构部分是重要的。研究神经网络的预测与最相似的训练数据点的关系的文献较少。为了实现这一目标,研究者开发了一种基于隐空间相似性的方法,即使用Molecular Transformer编码器对token取平均,将反应表示成固定长度向量,然后使用这些潜在空间向量的欧式距离寻找模型认为最相似的训练反应。研究者采用两种方式来验证他们这种方法。第一种方法是伪造样本,如果积分梯度在化学上不合理,即依据错误的原因预测出正确的结果,那么就设计对抗性样本,迫使模型做出错误的预测;第二种是寻找训练数据中预测的依据,如果预测错误,那么就询问训练数据中是否存在类似的错误条目。整体测试的流程如图1所示。接下来就以三个示例对研究者开发的方法进行说明:
示例1:环氧化反应的常用试剂是mCPBA,具有区域选择性。在第一个环氧化反应中,采用了mCPBA试剂,模型成功地预测出正确的结果(如图2a所示,蓝圈部分的积分为正,表示对正确预测选择性有贡献)。在另两个环氧化反应中采用的试剂是二甲基过氧化酮,它在训练数据中仅出现 14 次,且反应物的两个双键带有吸电子的取代基,尽管如此该模型也能正确预测(如图2b所示)。
示例2:Diels-Alder反应能将亲二烯体转化为具有双键的六元环。虽然亲二烯体一般优先与吸电子基团共轭,但Molecular Transformer却无法预测该反应的区域选择性(图3a)。图 3b 显示了基于模型编码器输出的训练集中最相似的3个反应,但第一个最相似的反应是错误的,第二个和第三个是 Grubbs复分解而不是环加成反应。这说明模型在潜在空间中没有很好地学习到 Diels-Alder反应。为此,研究者设计了一个对应于 [4 + 2] 环加成的反应模板,发现在数据库中只有七个反应与之匹配。由此可见,数据解释有助于识别错误样本和稀少样本引起的预测错误。
示例3:Friedel-Crafts反应的示例如图4所示。专利数据显示,90%的产物是对位的形式(与氟取代相比,酰基主要取代对位的氢)。Molecular Transformer正确预测了该反应。积分梯度计算表明该模型将正确预测归功于试剂因素,却忽略了氟在反应中的重要性。研究者通过使用间位取代基替换氟设计出对抗样本,模型就预测出了错误的结果。由此可见,模型在取代苯的 Friedel-Crafts 酰化反应中没有有效学习到选择性。在研究者给出的第三个Friedel-Crafts中,间位取代的贡献是负的,这意味着根据模型,酰胺基团有利于间位产物的形成,虽然这与化学原理一致,但该模型仍然预测对位是主要产物,这可能是因为训练数据集中的对位取代反应地数量远远多于间位取代反应的数量。
研究者也研究了训练数据的不平衡对模型的影响,如图5所示,尽管测试集中包含了相同数量的对位和间位取代产物,但当训练集中的间位和对位产物比例不同时,模型预测的结果也有所差异。当训练集间位和对位产物比例为1:1时,模型能迅速收敛并预测等量的间位和对位取代反应;当比例达到1:9时,模型产生偏差,但随着训练时间的延长,偏差会有所缓解;当比例达到1:99时,模型就无法预测出间位产物。由此可见,Molecular Transformer似乎只知道化学反应性,因此学习到了数据集中的隐藏偏差。
骨架偏差表现为训练集中骨架类似的分子通常参与非常相似的反应。研究者也研究了骨架偏差对模型的影响,如图6所示,研究者按照1:1将数据集拆分为训练集和测试集,分子的相似性采用分子指纹度量,许多训练集和测试集的反应非常相似。结果表明,测试集的57%-93%的反应产物与训练集中的产物结构相似,而且相似产物的反应通常也具有相似的原料和反应类型。因此,使用随机训练/测试拆分无法合理评估模型的预测和泛化能力。为了解释骨架的偏差,研究者建议训练集和测试集应依据产物的相似性划分,并确保测试集中没有任何反应的产物与训练集中的产物过度相似,同时训练集和测试集中不同反应类型的分布仍然遵循相似原则。数据划分完毕后,测试集中不存在不包含在训练集中的反应模板。划分后,测试集的模板去重数量从3k 增加到4.9k,这种拆分方法生成的数据集更具说服力。研究者按照上述方法处理了两个数据集,分别训练Molecular Transformer模型和一个基于图的反应预测模型。结果发现图模型和Molecular Transformer的表现均显著变差,但Molecular Transformer的表现依旧优于图模型(表1)。这些结果表明骨架偏差能显著影响基于图和基于序列的模型(这是数据集固有的性质,与模型架构无关)。
图表汇总

图 1. (a) 整体流程图;(b) 结构度输出的贡献;(c) 反应物和产物的空间编码。图片来源于Nature Communications

图 2. (a) 模型正确预测了环氧化反应;(b) 两个未知反应检验模型。图片来源于Nature Communications

图 3. (a) 模型对Diels-Alder反应预测的典型错误;(b) 模型未识别出Diels-Alder反应,或者训练集中这类反应很少。图片来源于Nature Communications

图 4. (a) 模型正确Friedel-Crafts酰化反应主产物是对位产物;(b) 当没有氟取代时,模型预测开始出现错误。图片来源于Nature Communications

图 5. (a) 数据集中的Friedel-Crafts反应分布情况;(b) 数据集中的偏差对模型产生了干扰。图片来源于Nature Communications
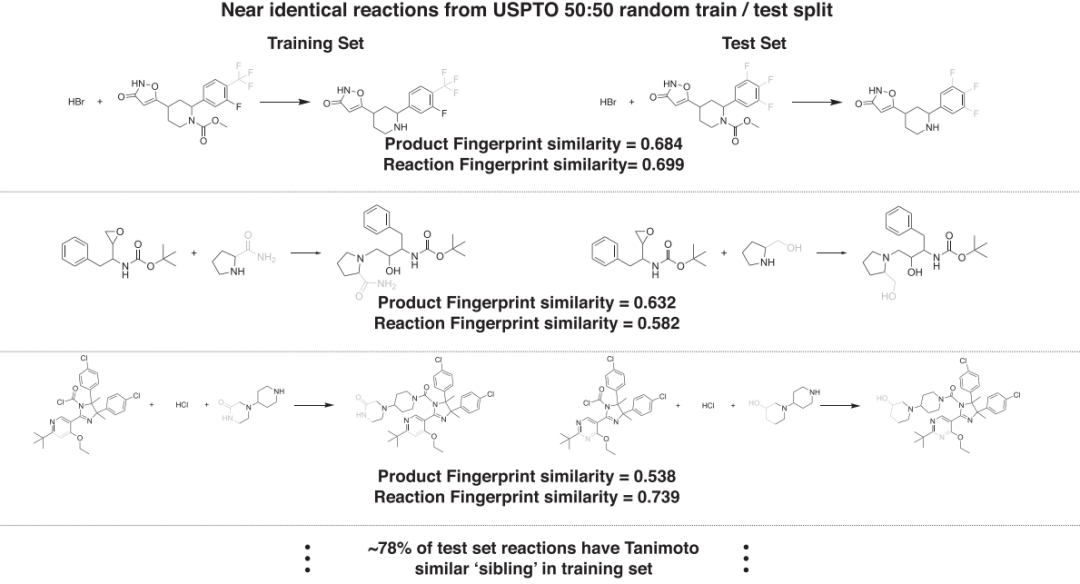
图6. 随机划分数据集时,训练集的样本和测试集的样本具有高度的相似性。图片来源于Nature Communications
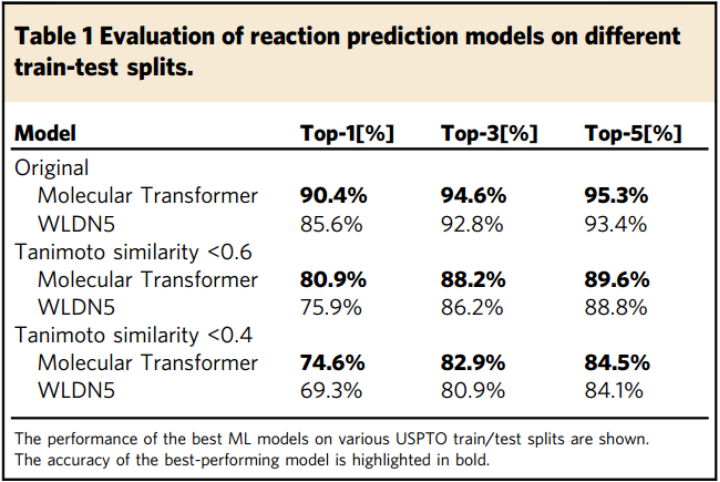
表1. 不同数据集划分方法中模型的表现。表格来源于Nature Communications
结论总结
研究者提出一个定量解释Molecular Transformer预测结果的框架,发现模型会通过学习偏差预测出正确的结果。研究表明,正确的预测可能是错误的训练样本引起的。研究者还发现了反应数据集中的骨架偏差现象,这种现象导致文献中模型的泛化性能被高估。研究者在新数据集上重新训练模型,发现模型准确率显著下降。通过严格应用可解释性技术,研究者揭示了发现模型弱点的方法,并希望该方法对数据科学家有所帮助。
参考文献
Dávid Péter Kovács, William McCorkindale, and Alpha A. Lee, Quantitative Interpretation Explains Machine Learning Models for Chemical Reaction Prediction and Uncovers Bias, Nature Communications, 2021, 12, 1695. DOI: 10.1038/s41467-021-21895-w.