欧洲分子生物学实验室于4月11日在Nature Reviews Drug Discovery发表了一篇关于机器学习在药物开发中应用的综述文章,该文章概述了当前机器学习中使用的工具和技术,并概述了迄今为止机器学习在关键制药领域中取得的进展。
药物发现的道路向来漫长、复杂并受诸多因素影响。机器学习(Machine learning)方法为药物发现提供了一系列工具,同时为还提供了众多高质量的数据信息。机器学习可以应用于药物发现的所有阶段,包括靶标验证,预后生物标记物的鉴定和临床试验中数字病理学数据的分析。目前许多制药公司已经将投资目标转向机器学习领域,通过支持机器学习方法的开发,促进新药研发。
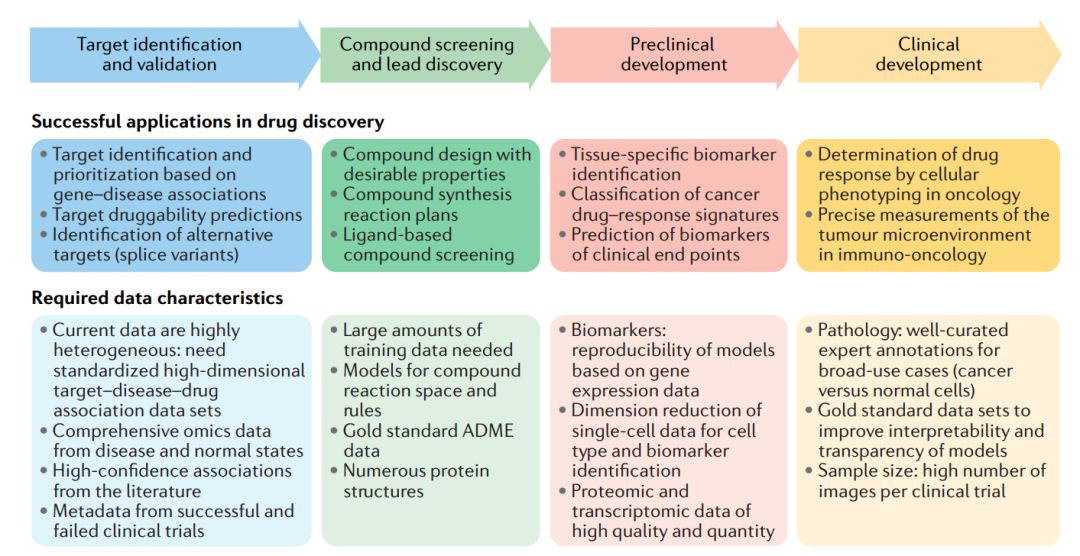
图1. 药物发现过程中机器学习的应用及其所具有的数据特征
如图1,机器学习方法已被应用于制药公司新药开发的各个步骤中。一个好的机器学习模型可以很好的将训练集数据泛化到手头的测试数据。泛化能力是指机器学习算法对新鲜样本的适应能力。如图2,每种计算方法的预测准确度、训练速度和它们可以处理的变量数量各不相同。
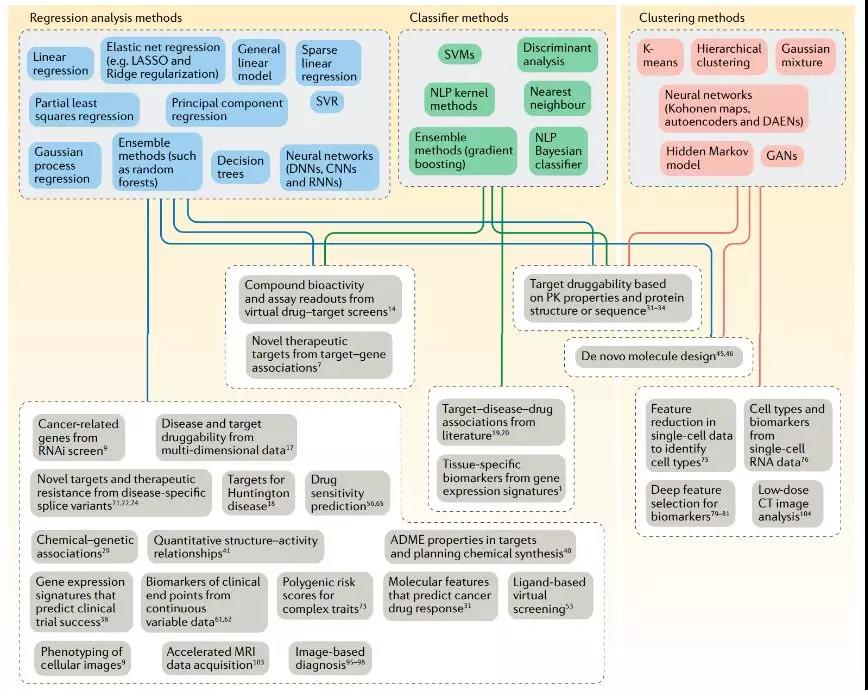
图2. 机器学习工具及其药物发现应用
ADME:吸收、分布、代谢和排泄;CNN:卷积神经网络;CT:计算机断层扫描;DAEN:深度自动编码器神经网络;DNN:深度神经网络;GAN:生成对抗网络;MRI:磁共振成像;NLP:自然语言处理;PK:药代动力学;RNAi:RNA干扰;RNN:递归神经网络;SVM:支持向量机;SVR:支持向量回归。
但机器学习方法的普遍应用会产生许多问题。例如,目前小分子设计领域尚未解决的问题是应用什么描述符代表化学结构。小分子结构存在大量的表示方法,从简单的圆形指纹如扩展连接指纹(Extended-connectivity fingerprint),到复杂的对称函数(如图3)。目前尚不清楚哪种结构表示最适合哪种小分子设计。在化学信息学领域机器学习研究的增加可能会为结构表征的最佳选择提供指导。
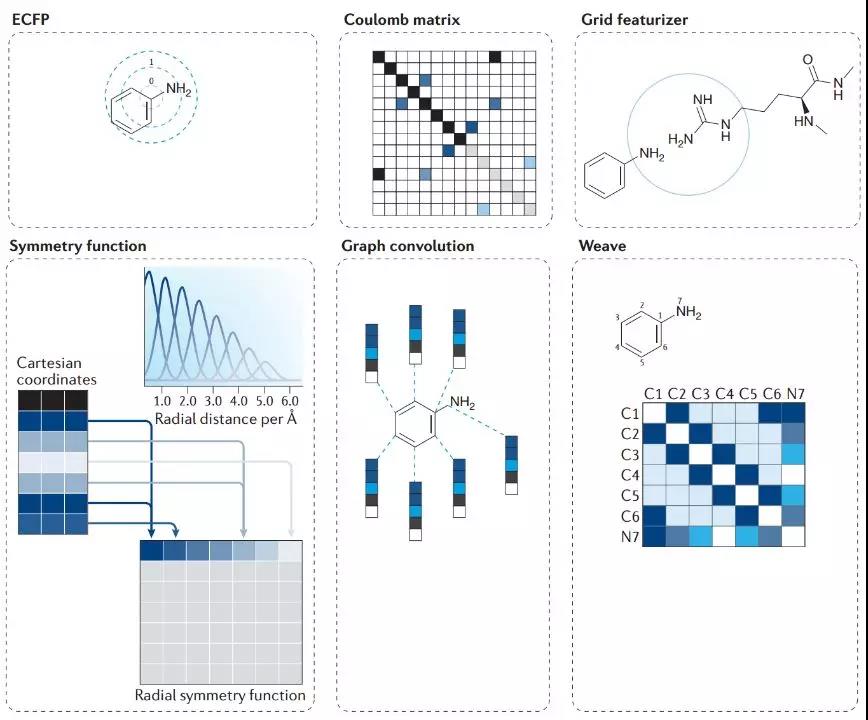
图3. 在机器学习模型中化合物结构表示方法所面临的挑战
利用预测生物标志物来实现药物开发(如图4),可以使用关于临床前数据的机器学习方法生成药物敏感性预测模型,然后应用来自早期临床患者样品的数据测试该模型。一旦经过验证,该模型便可用于患者分层或疾病指征选择,从而支持药物的临床开发并推断其作用机制。
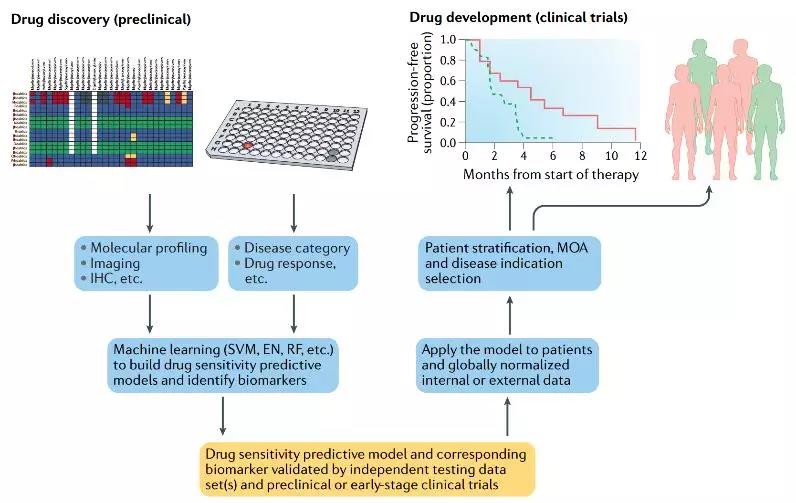
图4. 利用预测生物标志物来支持药物的研发
EN:弹性网;IHC:免疫组化;MOA:行动机制;RF:随机森林;SVM:支持向量机。
深度学习框架可以使用图像分割或特定特征的检测,取代基本病理图像识别任务(如细胞核,上皮细胞或小管的分割,淋巴细胞检测,有丝分裂检测或肿瘤分类)中的传统特征,并且更准确的预测疾病。
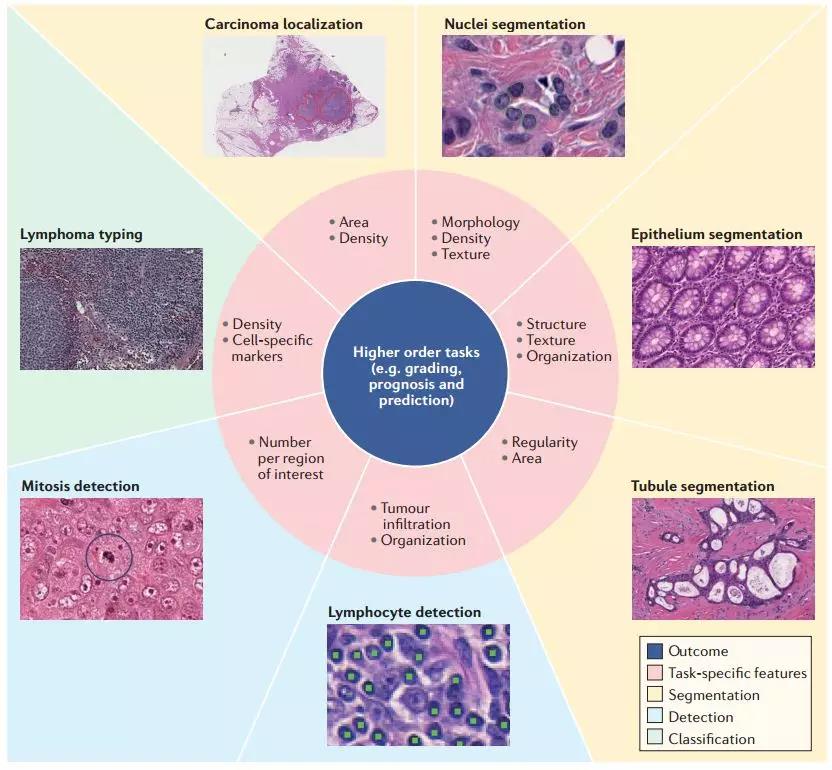
图5. 将机器学习算法应用于计算病理学任务
目前机器学习方法已被应用于药物发现的各个领域,特别是组学分析和成像数据分析。机器学习算法在语音识别、自然语言处理、计算机视觉和其他应用中也很成功。应用这种与互联网技术融合从而收集数据的机器学习方法,可以显著提高此类算法的预测能力,有助于医疗方案制定、提高治疗效益、获取临床生物标志物和降低药物副作用。
资料来源:Jessica Vamathevan, Dominic Clark, Paul Czodrowski, et. “Applications of machine learning in drug discovery and development.” Nature Reviews Drug Discovery (2019).