
引言
最近,有研究表明,某些抗癌药物与特定的小分子染料(如刚果红或IR783)共配,可以形成具有超高载药量的稳定纳米粒子。因此,研究者提出,通过赋形剂辅助联合组装的药物纳米颗粒,不仅限于化疗药物和化学染料,而且可以转移到更广泛的药物和赋形剂。但遗憾的是,目前还不清楚在数百万种可能的药物-赋形剂组合中,哪一种能够形成具有预期性能的纳米颗粒。
这篇文章中,研究者将分子动力学(MD)模拟和机器学习与一个高通量的实验共聚合平台相结合,可快速识别药物-赋形剂组合,从而在不需要化学合成的情况下,在溶剂交换的基础上可直接形成稳定的、自组装的固体药物纳米颗粒(研究者从788种候选药物和2686种辅料中,即共210万对可能的组合中,鉴定出100种新型共聚合固体药物纳米颗粒)。
用于共聚合识别的高通量平台
研究者选择了自聚集成胶体宏观结构的药物,作为他们平台的候选药物。前人的回顾性交叉验证实验中,随机森林模型可以识别出精度为77±2%的自聚集者。该模型确定了788种获得批准的药物有可能自聚集,在此,作为研究者的纳米颗粒配方平台的候选材料。其中,选择了20种化合物进行筛选,以跨越各种适应症,同时确保化学多样性。研究者使用动态光散射(DLS)确认了,这些候选药物的自聚集倾向,发现其中4种药物,没有显示可检测到的自聚集,因此被丢弃。其他16种药物形成微米大小的自聚集体,代表了不同的候选药物的共聚集体。同时,研究者从FDA非活性成分清单、FDA公认安全成分清单和FDA批准的其他小分子辅料中,选出了90个。除了作为阳性对照的刚果红,这些材料都没有用于,共聚集纳米颗粒。研究者采用纳米沉淀法,从药物和辅料组合中生成纳米颗粒。为了实现这一过程的自动化和提高重现性,研究者将液体处理平台与高通量DLS相结合。这使得研究者能够快速筛选出384孔板的纳米制剂,每次实验重复只使用1 nmol的药物或辅料。总的来说,研究者共生成了1440种配方,并通过实验测试了它们形成共聚集纳米粒子的能力。为了确定赋形剂是否会阻止其配对药物的胶体自聚集,研究者比较了药物赋形剂共聚集体的大小,与药物单独形成的胶体自聚集体的大小。在1440种测量的组合中,94种(6.5%)显示了目标尺寸的减少(图1b)。总体而言,数据表明,在不同的配对中,出现了具有不同行为的复杂分子识别机制。

图1. 固体药物纳米粒子的高通量筛选和机器学习模型开发
图片来源于Nat. Nanotechnol.
纳米粒子设计的机器学习
根据分子机器学习中的标准协议,研究者使用药物和辅料的化学子结构和物理化学性质,来描述每一对药物-赋形剂。此外,研究者在总结统计分子间距离、势能和动能的基础上,进行了短期的MD模拟,以量化药物和辅料之间的非共价相互作用势。这些计算,使得每对药物赋形剂生成了4515维描述符。如上所述,从高通量共聚集实验中,收集的1440个数据点被用作训练集(图1a和图1c)。鉴于随机森林机器学习模型,在分子机器学习方面的稳健性能和其内在的选择相关特征的能力,在此,研究者采用了随机森林机器学习模型。该模型在基于十倍交叉的回顾性评估中,表现出了良好的性能,并忽略一种药物的验证,这表明研究者的模型准确地捕捉了共聚集关系,并能够为一种新药物优先选择合适的辅料。
一个模型,包括所有参数类型是最准确的预测共聚集的结果,尽管特征重要性分析表明,模拟导出的定量分子相互作用和辅料的折射率,是最有信息的预测共聚集。参数烧蚀实验证实了,研究者的机器学习模型中最重要的特征相关性。最后,在训练数据的随机子集上训练的模型的袋外性能显示,模型性能正在收敛(图1d),表明额外进行的多轮筛选,很可能不会导致模型质量的显著改善,也不会提倡通过预测模型,更直接地获取额外数据。
为此,研究者使用他们的机器学习模型,对所有788种聚合药物,与2686种可用辅料中的任何一种组合的完整共聚合景观进行了建模。总计,共有210万种配方通过计算,评估了它们形成自组装共聚合纳米粒子的能力。考虑到对所有210万个组合进行MD模拟是不可行的,研究者应用了专门针对化学和物理化学性质训练的机器学习模型。改进后的模型回顾性表现稍低,但计算性较高。机器学习模型预测了,总共有38464种组合(1.8%的所有可能对)共聚集成纳米颗粒(图1e)。
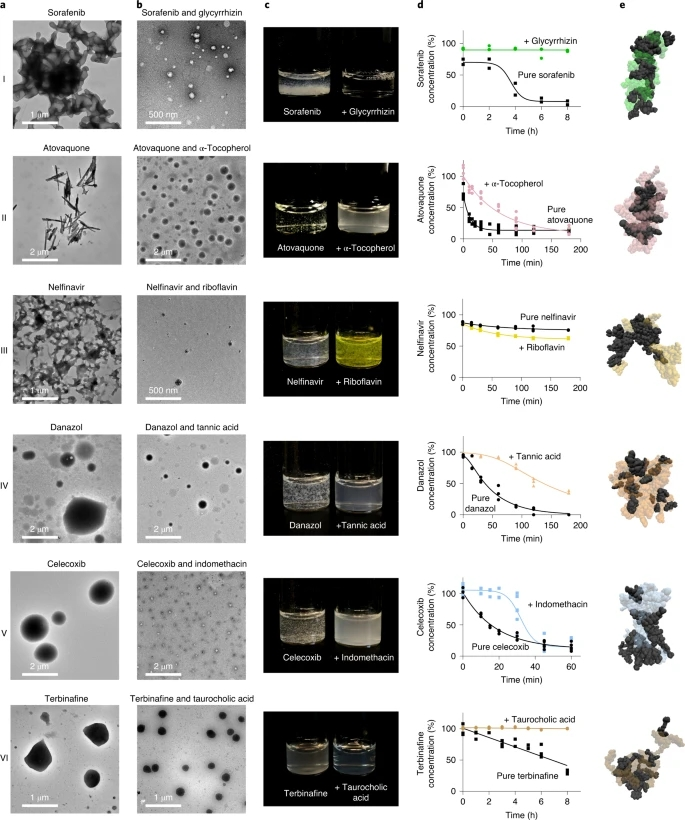
图2. 计算预测的药物-辅料组合形成纳米颗粒
图片来源于Nat. Nanotechnol.
经电脑模拟设计的纳米粒子改善了药物分散
在此,研究者选取了六种计算预测的共聚集组合进行实验测试,具体选择了新型辅料(图2, I-III)、新药(图2, IV和V)或新型药物与辅料的组合(图2,VI)。利用DLS来测量所选药物的胶体自聚集体的大小,这六种药物都自聚合成微米大小的多分散结构。透射电子显微镜(TEM),显示了一系列复杂的显微结构(图2a)。当药物与辅料混合时,DLS表明形成了单分散的纳米级共聚集体。利用透射电镜对药物辅料样品进行成像,证实所选药物与辅料共聚集形成均匀的纳米粒子群(图2b)。
为了进一步评估纳米颗粒分散的稳定性,研究者通过增加药物和辅料浓度来提高纳米颗粒浓度,同时在生产过程中保持药物与辅料的比例。除奈非那韦-核黄素外,所有的纳米颗粒共聚集体,在高达1 mM的高药物浓度下都表现出清晰或乳白色的分散;无赋形剂的药物迅速沉淀(图2c)。纳米颗粒形成了稳定的分散体,与不添加辅料的药物相比,纳米颗粒在较长时间内保持高药物浓度,但奈非那韦除外(图2d)。
为了研究控制共聚集的非共价力,研究者使用他们建立的参数,对20个药物和20个辅料分子的更大体系,进行了额外的MD模拟(图2e)。每个药物赋形体系统,都与特定的非共价力的不同模式相互作用,这表明纳米粒子的共聚集是由复杂的分子识别机制和各种非共价相互作用控制的。
展望与结论
基于小分子的纳米颗粒系统,是纳米医学的一个重要补充,使高负载的纳米载体快速产生,用于拯救生命的治疗。高载药量最终将降低赋形剂,引发不良反应的风险,减少给药量,提高依从性和生活质量。在此,研究者通过机器学习和高通量实验,扩大了这项技术的范围。
此外,聚集环境可以为适应性系统的发展提供进一步的机会,这种系统可以在特定的原位共聚集,例如在胃环境中。为了更好地选择特定的纳米粒子以适应不同的应用,利用相关方法,来预测这些纳米粒子的物理性质将是十分有用的。研究聚焦的纳米粒子组,可以实现尺寸预测。研究者提供了进一步的证据表明,纳米颗粒的大小与颗粒稳定性相关(图2)。此外,研究者数据表明,预测不确定性测量和MD分析,可以用于预测纳米颗粒的稳定性。预测生物分布和释放动力学等更复杂性质的模型,将进一步促进纳米颗粒的选择。通过加速纳米药物的发展,该方法及其扩展将是实现个性化药物输送的重要一步。
模型代码下载
https://github.com/DanReker/CoAggregators
参考文献
Daniel Reker, Yulia Rybakova, Ameya R. Kirtane, Ruonan Cao, Jee Won Yang, Natsuda Navamajiti, et al., Computationally Guided High-Throughput Design of Self-Assembling Drug Nanoparticles, Nature Nanotechnology, 2021, ASAP. DOI: 10.1038/s41565-021-00870-y.